:::tips
参会人:@提及
时间:2024-03-11
:::
项目需求
用户输入需求,利用ai生成智能图表,保存并返回给用户
建表
- 用户表
- 图表信息表 ```sql – 图表信息表 create table if not exists chartTable ( id bigint auto_increment comment ‘id’ primary key, goal text not null comment ‘分析目标’, chartData text null comment ‘目标图表数据’, chartType varchar(128) null comment ‘生成图表的类型’, genChart text null comment ‘生成的图表’, userId bigint not null comment ‘创建用户 id’, createTime datetime default CURRENT_TIMESTAMP not null comment ‘创建时间’, updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment ‘更新时间’, isDelete tinyint default 0 not null comment ‘是否删除’, ) comment ‘图表信息表’ collate = utf8mb4_unicode_ci;
<a name="y98Yh"></a>
# 项目思路整理
<a name="j1yFC"></a>
### 创新设计的个人思考
1. 用户拥有默认头像
1. 创建用户时存入默认头像或在前端展示默认头像
2. 搜索chart
1. 可以分页、按不同需求搜索某个用户创建的历史图表
3. ai生成回答格式不规范
1. 原因:程序化粗暴提取不可靠(ai生成内容有变)会导致程序稳定性降低
2. 当生成内容不规范时前端/后端检测到,内部校验后再重新生成
3. 获取ai生成的数据时用正则表达式提取代码和其他关键词
4. 脏数据(不规范数据)不存入数据库中
4. ai生成回答代码不统一
1. 有的代码包含title有的没有,导致生成图标渲染后格式不统一
2. 后端校验title参数(单独处理--反馈给前端)
5. 修改chart的vo设计
1. 有多余设计的字段
6. 获取用户的xlxs/csv文件可以用第三方库进行解析获取
7. **系统安全性**
1. 用户上传文件
1. 文件过大
2. 文件内容是否合法(数据格式,内容敏感)用第三方(腾讯云)的审核功能
3. 文件名称敏感(不合法)
4. 文件格式
2. 用户上传图片
1. 拓展:接入腾讯云的图片万象数据审核(cos对象存储的审核功能)
3. controller在调用ai前先进行登录校验等操作
<a name="whydA"></a>
### 项目个人优化
1. 自制api--openAI接口调用sdk(项目升级)
1. 自己设计自己的sdk
2. **亮点设计(项目升级)**
1. **当用户上传大量数据时用第三方(腾讯云)做文件秒传系统(文件大于100M)**
2. **实现文件分片上传(上传稳定性,速度)**
3. **图片存储从地址改为文件类型(进行中--不可以调用用户增删改查接口)**
1. **存储图片输入流字符串**
1. **读取时转换输入流字符串**
2. **修改数据库/mapper中头像存储类型**
2. 允许用户上传头像时上传图片文件
1. picmanager处理,思路
1. 文件读取并转换为二进制字节数组
2. 存储字符串不存储二进制数组,读取时把字符串转为二进制数组再读取
3. 前端得到二进制数据如何展示头像(展示文件格式)---接口设计--》给前端二进制数组/字符串?
3. **手动进行头像属性的赋值(vo中接收头像为文件/实体类中头像为byte[])**
4. **图片合规性校验**
4. 用户更新个人资料时某些值不上传则保存原来的值(在用户资料页更新,从数据库中读取个人信息,不上传的保存为原本的值)
<a name="TYVQ1"></a>
### 数据库表设计
<a name="OFlGC"></a>
#### 知识点
1. 分库分表
1. ·水平分表
2. 垂直分库
2. Mybatis的动态sql
3. mybatis-plus
4. **int搜索比varchar要快,数据库存储枚举字段时用枚举值代替**
<a name="HaFdY"></a>
#### 原始数据与生成图表代码如何存储
1. mongodb存储原始数据文件(后续升级)
1. 引入mongodb,不使用实体类映射表格
2. 动态sql存储文件
2. 分表存储chart
1. 使用动态sql存储图表,不使用映射关系
<a name="VY5UU"></a>
#### 分库分表设计
优化设计:垂直分表!
> 垂直分表是基于数据库中的"列"进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。在字段很多的情况下(例如一个大表有100多个字段),通过"大表拆小表",更便于开发与维护,也能避免跨页问题
更利于数据的扩展
1. chartdata图表原始数据过大,新建对应的数据表存放(关联表)
2. gendata生成图表代码过大如何存储
3. 如果存在同一个表里,有单一数据过大影响整个表的查询性能
实现
1. 创建chart_data表
字段设计<br />根据你的需求,你想要将 `genChart` 和 `chartData` 字段独立出来进行水平分表,而新的表与原始表进行关联。为了合理设计新表,你需要考虑到以下几点:
1. **如何关联原始表:** 新表需要一个字段来与原始表进行关联,以便能够知道每条数据属于哪个原始表的记录。
2. **保留原始表的主键信息:** 新表需要保留原始表的主键信息,以便能够在查询时定位到正确的记录。
基于以上考虑,你可以设计一个新表,包含以下字段:
- **id(主键):** 作为新表的主键,保留原始表的主键信息。
- **chart_id(外键):** 与原始表的 `id` 字段进行关联,表示该记录属于哪个原始表的图表信息。
- **genChart:** 存储 `genChart` 字段的内容。
- **chartData:** 存储 `chartData` 字段的内容。
```sql
CREATE TABLE chart_data (
id bigint auto_increment comment 'id' primary key,
chart_id bigint not null comment '图表信息表的id',
genChart text null comment '生成的图表',
chartData text null comment '目标图表数据',
foreign key (chart_id) references chart(id)
) comment '图表核心数据表' collate = utf8mb4_unicode_ci;
在这个设计中,chart_data 表中的 chart_id 字段与原始表 chart 中的 id 字段进行关联,以保证每条记录都能够正确地对应到原始表中的相应记录。这样设计可以提高查询效率,同时保留了数据的关联性。
- 给chart表的主键添加索引
- 在这种情况下,为了提高查询
chart表数据的效率,应该在chart表中的chart_id字段上建立索引,而不是在chart_data表中的外键上建立索引。
原因如下:
- 查询主要针对 **
**chart**表:** 你主要关心的是查询chart表中的数据,而不是chart_data表中的数据。因此,为了加速对chart表的查询,你应该在chart表中的chart_id字段上建立索引。 - 外键不一定需要单独索引: 在大多数情况下,数据库会自动为外键建立索引。因此,通常情况下不需要为外键额外建立索引。而且,在这种情况下,为
chart_data表的外键建立索引并不会直接提高对chart表的查询效率。
因此,建议你在 chart 表中的 chart_id 字段上建立索引,以加速对 chart 表的查询。这样可以更有效地优化查询性能。
要在 chartCoreData 表的 chartId 字段上创建索引,使用如下的 SQL 语句:
CREATE INDEX idx_chart_chart_id ON chart (chart_id);
这条 SQL 语句将在 chart 表的 chart_id 字段上创建一个名为 idx_chart_chart_id 的索引。索引的作用是加速对 chart 表中 chart_id 字段的查询操作,提高查询效率。
执行以上 SQL 语句后,数据库系统会在 chart_id 字段上创建索引,使得查询操作更加高效。
实现
存储
- 存储
/** * 生成图表存储 */ // 生成图表代码存储至图表核心数据类 ChartCoreData finishCoreData = new ChartCoreData(); // 存储chartId finishCoreData.setChartId(chartId); finishCoreData.setChartData(csv); finishCoreData.setGenChart(code); boolean coreSave = chartCoreDataService.save(finishCoreData); // 保存生成结论,修改生成成功更改状态 Chart.setGenResult(analyse); Chart.setChartStatus(ChartConstant.SUCCEED); boolean succeed = ChartService.save(Chart);查询
- 把chartCoreData中字段查询出后塞入Chart实体类中返回
- 根据chartId(字段名查询)构造queryWarpper
/** * queryWrapper构造根据chartId查询chart核心数据 * @param chartId * @return */ private QueryWrapper<ChartCoreData> getQueryCoreWrapper(Long chartId) { QueryWrapper<ChartCoreData> queryCoreWrapper = new QueryWrapper<>(); if (chartId == null) { return queryCoreWrapper; } queryCoreWrapper.eq("chartId", chartId); return queryCoreWrapper; }对于普通查询
Long chartId = chart.getId(); ChartCoreData coreData = chartCoreDataService.getOne(getQueryCoreWrapper(chartId)); chart.setGenChart(coreData.getGenChart()); chart.setChartData(coreData.getChartData());对于page分页查询,每一个都要回传
Page<Chart> ChartPage = ChartService.page(new Page<>(current, size), getQueryWrapper(ChartQueryRequest)); // 从chartCoreData中获取数据传回chart实体类中 for (Chart chart : ChartPage.getRecords()) { Long chartId = chart.getId(); ChartCoreData coreData = chartCoreDataService.getOne(getQueryCoreWrapper(chartId)); chart.setGenChart(coreData.getGenChart()); chart.setChartData(coreData.getChartData()); }对于分查询后传回VO类,编写VO转换函数 ```java /**
- 返回chartVO分页查询类
- @param chartPage
- @return
*/
@Override
public Page
getChartVOPage(Page chartPage) { List charts = chartPage.getRecords(); List chartVOS = new ArrayList<>(); for (Chart chart : charts) { ChartVO chartVO = this.ChartToChartVO(chart); chartVOS.add(chartVO); } Page voPage = new Page<>(); BeanUtils.copyProperties(chartPage, voPage); voPage.setRecords(chartVOS); return voPage; }
- 根据chartId(字段名查询)构造queryWarpper
由于vo中有userVO对象,查询后插入返回 /** * 获得chart包装类(包含userVo) * @param chart * @return */ @Override public ChartVO ChartToChartVO(Chart chart) { if (chart == null) { return null; } ChartVO chartVO = new ChartVO(); User user = userService.getById(chart.getUserId()); UserVO userVO = userService.getUserVO(user); BeanUtils.copyProperties(chart, chartVO); chartVO.setUserVO(userVO); return chartVO; }
<a name="ewqPw"></a>
#### 单表查询优势
使用单表查询而非连表查询理由
1. 效率:使用两次数据库查询+service层计算组装优势联表查询是笛卡尔乘积方式,两表数据量大时检索数据是几何倍上升的
2. 缓存利用率更高:关联查询,任何一张表数据变动都会引起缓存失效
3. 更灵活:单表查询更利于维护,如果某个表结构变动,单表查询由于是分开查询操作,只会影响其中某个查询操作
<a name="zoFoP"></a>
# 项目问题具体优化和实现
<a name="wtUFx"></a>
### ai生成回答格式不规范
1. option函数有多余代码,用正则匹配option函数
option\s=\s({[^;]*});
```java
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
public static void main(String args[]) {
String str = "";
String pattern = "option\\s*=\\s*({[^;]*});";
Pattern r = Pattern.compile(pattern);
Matcher m = r.matcher(str);
System.out.println(m.matches());
}
}
- 正则匹配结论部分
要匹配出最后一个之后所有文本的正则表达式,但不包含字符串,可以使用以下正则表达式:
(?<=```)[^`]*$
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
String input = "This is a test string.\n```java\nSystem.out.println(\"Hello, World!\");\n```\nAnother test string.";
String regex = "(?<=```)[^`]*$";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
System.out.println("Found: " + matcher.group());
}
}
}

- 接入星火模型ai返回值

项目核心功能进度

待修正bug
前后端联调有问题 (√)
登陆后无法跳转到我的图表页面查询出图表信息但是无法在前端展示redisson
- 引入
- redisson-springboot-starter
- 该方式可以直接使用redissonClient,但要注意starter与springboot的版本
- redisson直接引入
- 该方式需要自己设置参数(config类)
- redisson-springboot-starter
- 配置






项目技术栈
多线程异步化处理
资源隔离策略:重要任务一个队列优先级更高,普通任务一个队列,优先级更低,保证两个队列互不干扰
线程池
设计
- 使用JUC的线程池
- 核心参数设置(参考别的ai调用服务)
Redis
分页的目的是为了提高用户体验
分页是一个有挑战性的功能,尤其是在数据量很大、更新频率很高、查询条件很多的情况下。如果我们直接使用传统的数据库来实现分页,我们可能会遇到以下的问题:
- 数据库压力过大:如果每次分页都要从数据库中查询数据,那么数据库就要承担很大的压力,尤其是在高并发的情况下,数据库可能会出现性能下降、连接超时、锁等待等问题。
- 查询效率低下:如果我们使用SQL语句来实现分页,我们可能会使用LIMIT、OFFSET等关键字来指定查询范围,但是这样做会导致查询效率低下,因为数据库要扫描所有符合条件的数据,然后再跳过前面的数据,返回后面的数据。这样做会浪费很多资源和时间,尤其是在分页数较大的情况下。
- 数据一致性难以保证:如果我们使用缓存来减轻数据库压力和提高查询效率,我们可能会遇到数据一致性的问题。因为缓存和数据库之间可能存在延迟或者不同步,导致用户看到的数据和实际的数据不一致。例如,用户看到了已经被删除或者修改的数据,或者没有看到最新添加或者更新的数据。
参考文章 : https://developer.aliyun.com/article/1171184
https://www.cnblogs.com/shoshana-kong/p/17475047.html
缓存经常需要查询的热点数据,图表信息一旦生产不轻易修改
Redis的分页实现
我们通常习惯于在Mysql、Oracle这样持久化数据库中实现分页查询,但是基于某些特殊的业务场景下,我们的数据并未持久化到了数据库中或是出于查询速度上的考虑将热点数据加载到了缓存数据库中。因此,我们可能需要基于Redis这样的缓存数据库去进行分页查询。
Redis的分页查询的实现是基于Redis提供的ZSet数据结构实现的,ZSet全称为Sorted Set,该结构主要存储有序集合。下面是它的指令描述以及该指令在分页实现中的作用:
- ZADD:SortedSet的添加元素指令ZADD key score member [[score,member]…]会给每个添加的元素member绑定一个用于排序的值score,SortedSet就会根据score值的大小对元素进行排序。我们为通常习惯于将数据的时间属性当作score用于排序,当然大家也可以根据具体的业务场景去选择排序的目标。
- ZREVRANGE:SortedSet中的指令ZREVRANGE key start stop可以返回指定区间内的成员,可以用来做分页。
- ZREM:SortedSet的指令ZREM key member可以根据key移除指定的成员,能满足删评论的要求。
所以SortedSet用来做分页是非常适合的。下面是分页实现的演示图,包含插入新记录后的查询情况。
Redisson
限流校验
public class RedissonManager {
@Autowired
private RedissonClient redissonClient;
public void doReteLimiter(String keyName){
RRateLimiter rateLimiter = redissonClient.getRateLimiter(keyName);
/**
* 已经设置了rate,则trySetRate返回为True,否则为false
*/
log.info(Thread.currentThread().getName());
rateLimiter.trySetRate(RateType.OVERALL, 2, 1, RateIntervalUnit.SECONDS);
// todo 验证令牌延迟发放问题是否与try acquire有关
boolean canOp = rateLimiter.tryAcquire(1);
if (!canOp){
throw new BusinessException(ErrorCode.TOO_MANY_REQUEST, ErrorCode.TOO_MANY_REQUEST.getMessage());
}
}
}
/**
* 限流校验
*/
redissonManager.doReteLimiter("genChart_" + loginUser.getUserAccount());
rabbitMq
面试题
消息的可靠性 四种 return confirm 高可用(集群) 持久化
MQ应用场景 顺序消费 服务间异步提速 定时任务 应用解耦 肖风填谷
队列的四种模式
持久化缺点 降低服务器吞吐量 增加了io次数 对应就减少了吞吐量
原生的消费端实现步骤
1.创建连接工厂 2.设置五个必要参数 3.创建连接 4.通过连接创建管道 5.创建队列
MQ和网关有什么不同,都是对请求来判断往哪里送
网关: 服务器与用户之间
MQ: 服务器与服务器之间
死信队列+重试机制
项目中有关mq部分架构设计
- 前端基础数据先传入数据库
- 获得图表id并返回
- id作为消息放入工作消息队列(消息设计)
- 本服务器一个消费者从(暂定,多个消费者or单个区别?)消息队列中取出id再进行ai耗时操作
- 消息放入死信队列(重新入队列or死信队列区别)
- 如果ai生成图表失败,抛异常,启动重试机制
- 如果连续重试5次还是无法处理消息,进入“死信队列”
- 队列已满(√)
- 队列长度设计?
- 消息过期(不设置过期时间)
- 如果ai生成图表失败,抛异常,启动重试机制
- 死信队列处理
- 在MQ消费者底层的发生故障,比如发生数据库宕机、缓存宕机等情况时,消费者系统就无法完成消息的处理,此时可以通过一些返回状态让消息进入 MQ 自带的重试队列;如果重试5次消息处理后还是失败,就可以让消息进入RocketMQ自带的死信队列,后续针对死信队列中的消息进行单独的处理就可以了。
- 丢弃消息,只更改数据库记录为失败状态并记录失败具体信息
重试机制
首先说一下RabbitMQ的消息重试机制,顾名思义,就是消息消费失败后进行重试,重试机制的触发条件是消费者显式的抛出异常
还有一种情况就是消息被拒绝后重新加入队列,比如basic.reject和basic.nack,并且requeue = true,但是个人认为这个不算是触发了重试机制,这个是重新进入到了消息队列然后重新被消费,并且也不会触发我们重试机制的配置(如重试间隔、最大重试次数等等)。
重试机制是默认开启的,但是如果没有重试机制相关的配置会导致消息一直无间隔的重试,直到消费成功,所以要使用重试机制一定要有相关配置。
需要说明的是,上述的方法一定要开启自动ACK,才会在到达最大重试上限后发送到死信队列,而且在重试过程中会独占当前线程,如果是单线程的消费者会导致其他消息阻塞,直至重试完成,所以可以使用@RabbitListener上的concurrency属性来控制并发数量。延时队列设计
参考文章: https://baobao555.tech/archives/45
用户注册成功后,如果超过24小时没有登录则进行短信提醒 ``` 我们既可以控制消息在一段时间后变成死信,又可以控制变成死信的消息被路由到某个指定的交换机。结合这2点就可以实现一个延时队列
我们可以先给一个普通的交换机发送我们希望具有延时功能的消息,该交换机将这些消息放到一个特殊的队列
<a name="e69sQ"></a>
### 代码实现
运行成功<br />在重试五次之后<br />进入死信队列<br />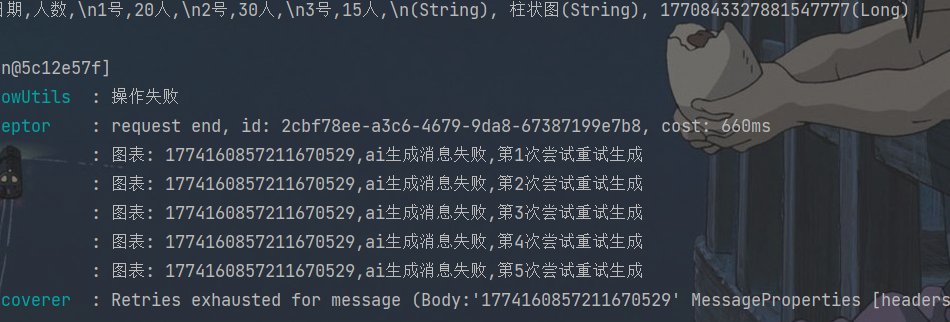<br />
<a name="AG81L"></a>
# 支付宝沙箱测试
参考文章:<br />阿里云开发者社区 : [https://developer.aliyun.com/article/1423176#slide-0](https://developer.aliyun.com/article/1423176#slide-0)<br />黑马博客 理论+代码: [https://www.itheima.com/news/20221110/152304.html](https://www.itheima.com/news/20221110/152304.html)<br />掘金 代码:[https://juejin.cn/post/6949080286093115423](https://juejin.cn/post/6949080286093115423)<br />支付宝沙箱官网介绍: [https://opendocs.alipay.com/common/02kkv7](https://opendocs.alipay.com/common/02kkv7)<br />支付宝沙箱是支付宝提供的一个模拟环境,用于开发者进行支付宝相关功能的测试和调试。在支付宝沙箱中,开发者可以模拟用户支付、退款等操作,而不会产生真实的交易流水和资金变动。这样可以帮助开发者在开发过程中更加方便地调试和验证支付宝集成的功能,确保系统稳定性和安全性。
实现<br />内网穿透测试成功<br />使用内网穿透测试访问程序的一个接口,测试成功<br />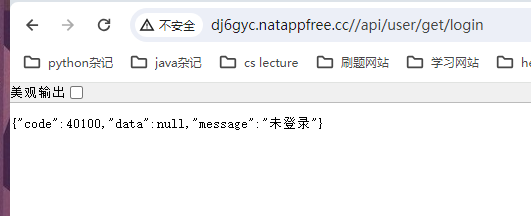
<a name="j0FTi"></a>
# 项目确定优化功能
看一下权限校验的注解 <br />看一下aop完成了什么功能 (打日志)<br />分页查询如何实现的
1. ~~水平分表(chart表数据与生成代码单独保存)~~
2. ~~前端添加注册功能+换接口--》使用了mq的接口()~~
3. ~~删除多余业务逻辑~~
4. 支付宝代码沙箱
5. **redis存储chart表,减小批量查询压力(!)**
6. ~~添加计数字段,每个用户设置调用次数(后期充值补充字段)~~(√)
7. 联表查询(查询一次数据库)**单表查询缓存利用率更高** 比如上面查询中的tag是不常变动的数据,缓存下来,每次查询就可以跳过第一条查询语句。而关联查询 - 搜索结果 ,任何一张表的数据变动都会引起缓存结果的失效,缓存利用率不会很高。
8. 单表查询+代码上组装的方式。使用Stream lambda + [mybatis plus](https://www.zhihu.com/search?q=mybatis%20plus&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A2071090987%7D) + lombok
<a name="fucRT"></a>
# 已对接接口
<br />http://localhost:8101/api/aiFrequency/get
<a name="cuP83"></a>
## ai聊天模块 (√)
完全复制ai生成图片模块但是不用上传文件-->对其接口,状态值与传递,返回参数就ok<br />个人信息页面模块
1. 查询剩余使用ai次数调用函数(√)
- [ ] 添加事务:加锁--确保事务的一致性 todo
1. 扣除了次数一定要调用ai服务
1. http://localhost:8101/api/aiFrequency/get
2. 
**这两个字段可以补充在用户表中**
```javascript
const loadData = async () => {
try {
const res = await getAiFrequencyUsingGET();
// console.log('用户次数', res.data);
if (res.data) {
setFrequency(res.data);
}
} catch (e: any) {
message.error('获取数据失败' + e.error);
}
};
- 获取用户信息页面(多了很多字段)

支付宝支付模块
完全可以仿照ai查询图表的接口cv开发!
- 支付信息查询
http://localhost:8101/api/payInfo/list/my/page

- 订单付款页面
http://localhost:8101/api/order/my/list/page
- 个人订单页面
