设计流程
- 调研相关系统
- 项目模块设计
业务代码代码设计注意事项
- 定义枚举类与定义常量标识的场景
- 枚举类可以拥有更多属性和方法
- 调用得到所有的枚举值的特定属性
- 枚举类可以拥有更多属性和方法
- id生成规则
- tableId(Type = ASSIGN_ID)
- 非连续自增
- 23年idea自动reload代码(不重启
- 传递参数的类设置字段类使用包装类,可以不传递该参数,没有默认值
- int 默认值0
- Integer 没有默认值
- wrapper的like方法,true时拼接查询条件
- 登录态过期时间自定义(session设置时间)
ProcessBuilder进程管理控制
public void getProcessByCmd(String logFilePath, String codeFilePath) {
// TODO
ProcessBuilder pb = new ProcessBuilder("java","Main", "1", "2");
// 暂时性更改
System.setProperty("console.encoding", "UTF-8");
// Map<String, String> env = pb.environment();
// env.put("VAR1", "myValue");
File file = new File(codeFilePath);
pb.directory(file);
String userLogFile = logFilePath + File.separator + "myLog";
File codeLog = new File(userLogFile);
pb.redirectErrorStream(true);
pb.redirectOutput(ProcessBuilder.Redirect.appendTo(codeLog));
try {
Process p = pb.start();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
在 Java 中,你可以通过指定一个已存在的目录来设置进程的工作目录,而不是新建一个文件。这可以通过 ProcessBuilder 类的 directory 方法来实现。
下面是一个简单的示例,演示了如何指定一个已存在的目录作为进程的工作目录:
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
// 指定已存在的目录作为工作目录
File workingDirectory = new File("/path/to/your/existing/directory");
// 创建 ProcessBuilder 对象并设置工作目录
ProcessBuilder pb = new ProcessBuilder("myCommand", "myArg1", "myArg2");
pb.directory(workingDirectory);
// 后续操作...
}
}
在这个示例中,我们首先创建了一个 File 对象来表示已存在的目录,然后将其作为参数传递给 ProcessBuilder 的 directory 方法。这样就可以确保新进程在执行命令时使用指定的已存在目录作为工作目录,而不会创建一个新的文件。
通过这种方式,你可以明确指定进程的工作目录,以确保命令执行时所处的环境符合预期。
环境参数影响
这些环境变量在执行外部命令时可以影响命令的参数构成和进程的行为:
- 影响命令的参数构成:
- 通过
env.put("VAR1", "myValue");和env.put("VAR2", env.get("VAR1") + "suffix");这样的代码,你可以向进程的环境变量中添加自定义的变量。这些变量可以在执行外部命令时被读取和使用,从而影响命令的参数构成。例如,命令可能会根据环境变量的不同而执行不同的逻辑或操作。
- 通过
- 影响进程的行为:
- 进程的环境变量可以影响进程的行为和执行结果。某些命令可能会根据特定的环境变量来改变其行为,或者使用环境变量中的值来进行计算或决策。因此,通过设置环境变量,你可以对进程的行为产生影响,例如指定特定的工作目录、配置参数或提供必要的信息。
总的来说,环境变量的设置可以使你在执行外部命令时灵活地控制命令的参数构成和影响进程的行为,从而实现定制化的功能和操作。
编码
- 查看控制台编码
chcp
使用 chcp 命令来临时更改控制台的代码页。要将控制台的代码页设置为 UTF-8,可以执行以下命令:
chcp 65001
执行此命令后,控制台的代码页将被设置为 UTF-8,从而允许正确显示和处理 UTF-8 编码的文本。请注意,这种更改是临时的,只在当前会话中有效。若要永久更改控制台的代码页,请参考之前提供的注册表编辑方法。
永久更改控制台编码
在 Windows 中,可以通过更改注册表来永久设置控制台的默认代码页为 UTF-8。请按照以下步骤操作:
- 打开注册表编辑器:
- 在 Windows 中,按下
Win + R打开运行对话框,然后输入regedit并按 Enter 键。
- 在 Windows 中,按下
- 导航到控制台设置的位置:
- 在注册表编辑器中,转到以下路径:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Console
- 在注册表编辑器中,转到以下路径:
- 创建一个新的字符串值:
- 在右侧窗格中,右键单击空白处,选择 “新建” -> “字符串值”。
- 将新值命名为
CodePage。
- 设置字符串值的数据:
- 双击新创建的
CodePage值,将其数值数据设置为65001(UTF-8 对应的代码页编号)。
- 双击新创建的
- 重新启动计算机:
- 更改注册表后,为了使更改生效,需要重新启动计算机。
完成以上步骤后,控制台的默认代码页就会被永久设置为 UTF-8,这样在控制台中就可以正确显示和处理 UTF-8 编码的文本了。请在更改注册表时小心谨慎,确保不要更改其他重要的设置。
stopWatch
在使用stopWatch时,如果开启一个task,不调用 stopWatch.stop();的话
long totalTimeMillis = stopWatch.getTotalTimeMillis();
获取到的totaltime为0
同样情况下,不调用 stopWatch.stop();的话
long lastTaskTimeMillis = stopWatch.getLastTaskTimeMillis();
方法会报错:Exception in thread "main" java.lang.IllegalStateException: No tasks run: can't get last task interval
public static void stopWatchTest(){
StopWatch stopWatch = new StopWatch();
stopWatch.start("task1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// stopWatch.stop();
long totalTimeMillis = stopWatch.getTotalTimeMillis();
System.out.printf("totalTimeMillis: %d\n", totalTimeMillis);
long lastTaskTimeMillis = stopWatch.getLastTaskTimeMillis();
System.out.printf("totalTimeMillis: %d\n", lastTaskTimeMillis);
}
如果要一直不间断的检测代码进程是否存活(while(true)) 1. 浪费资源 2. 太严格,没意义
所以选择隔一段时间检测代码进程存活情况:
- 直接在设置最大存活时间时检测,
- 如果此时代码进程仍存活说明肯定运行超时,直接终止该进程
- 进行后续异常终止处理收集结果(检测所有输入用例消耗时间是否超时,只开一个守护线程)
- 如果此时进程已经终止,判断是守护线程杀死还是主动结束的
- 输入用例size==输出结果size
- 程序顺利运行结束
- 说明在最大规定时间内执行结束程序,正常获取每次的stopwatch结果计时即可
- 输入用例size==输出结果size
- 如果此时代码进程仍存活说明肯定运行超时,直接终止该进程
实体类
字段属性要对应,否则依赖mybatis框架查询出来的字段不会自动填充到实体类中
- @TableField(exist = false)注解通常用于Java中的ORM框架,比如MyBatis或者Hibernate。这个注解的作用是告诉ORM框架在数据库表中不存在与之对应的字段,这样在进行数据库操作时,ORM框架就会忽略这个字段,不会将其纳入到SQL语句中。这在一些特定的业务场景下非常有用,比如在实体类中定义了一些与数据库表无关的计算字段或者临时字段时,可以使用这个注解来标识这些字段。
- 数据库字段实体类的作用和意义在于将数据库表中的字段映射到对应的Java实体类中,这样可以通过对象来表示数据库中的数据,从而方便在代码中进行操作和处理。通过实体类,可以将数据库表的结构和数据操作封装成对象,提高了代码的可读性和可维护性。
数据库字段实体类的作用和意义包括:
- 数据结构映射:实体类中的属性通常对应数据库表中的字段,通过实体类可以清晰地了解数据库表的结构和字段含义。
- 数据操作封装:实体类中可以定义数据操作的方法,比如数据验证、数据转换等,使得对数据的操作更加方便和安全。
- 对象化操作:使用实体类可以将数据库表中的数据转换为对象,从而可以更加方便地在代码中进行操作,比如传递对象作为参数、返回对象作为结果等。
- ORM框架支持:很多ORM(对象-关系映射)框架都支持将数据库表映射为实体类,通过实体类可以方便地进行数据库操作,减少了手动编写SQL语句的工作量。
总之,数据库字段实体类的作用和意义在于提供了一种对象化的方式来处理数据库表中的数据,使得数据操作更加直观、方便和安全。
Springboot相关
bean
互相循环依赖,另一个bean添加懒启动注解 @Lazy
strem流和lamdb表达式
public Page<QuestionSubmitVO> getQuestionSubmitVOPage(Page<QuestionSubmit> questionSubmitPage, User loginUser) {
List<QuestionSubmit> questionSubmitList = questionSubmitPage.getRecords();
Page<QuestionSubmitVO> questionSubmitVOPage = new Page<>(questionSubmitPage.getCurrent(), questionSubmitPage.getSize(), questionSubmitPage.getTotal());
if (CollectionUtils.isEmpty(questionSubmitList)) {
return questionSubmitVOPage;
}
List<QuestionSubmitVO> questionSubmitVOList = questionSubmitList.stream()
.map(questionSubmit -> getQuestionSubmitVO(questionSubmit, loginUser))
.collect(Collectors.toList());
questionSubmitVOPage.setRecords(questionSubmitVOList);
return questionSubmitVOPage;
}
/**
* 提交用户信息
*/
private UserVO userVO;
/**
* 对应题目信息
*/
private QuestionVO questionVO;
/**
* 对应题目信息
*/
private QuestionVO questionVO;
/**
* 包装类转对象
*
* @param questionSubmitVO
* @return
*/
public static QuestionSubmit voToObj(QuestionSubmitVO questionSubmitVO) {
if (questionSubmitVO == null) {
return null;
}
QuestionSubmit questionSubmit = new QuestionSubmit();
BeanUtils.copyProperties(questionSubmitVO, questionSubmit);
JudgeInfo judgeInfoObj = questionSubmitVO.getJudgeInfo();
if (judgeInfoObj != null) {
questionSubmit.setJudgeInfo(JSONUtil.toJsonStr(judgeInfoObj));
}
return questionSubmit;
}
/**
* 对象转包装类
*
* @param questionSubmit
* @return
*/
public static QuestionSubmitVO objToVo(QuestionSubmit questionSubmit) {
if (questionSubmit == null) {
return null;
}
QuestionSubmitVO questionSubmitVO = new QuestionSubmitVO();
BeanUtils.copyProperties(questionSubmit, questionSubmitVO);
String judgeInfoStr = questionSubmit.getJudgeInfo();
questionSubmitVO.setJudgeInfo(JSONUtil.toBean(judgeInfoStr, JudgeInfo.class));
return questionSubmitVO;
}
在这段代码中,.map(questionSubmit -> getQuestionSubmitVO(questionSubmit, loginUser)) 使用了Java 8的Stream API中的map方法。在这里,map方法将会遍历questionSubmitList中的每一个QuestionSubmit对象,并对每个对象应用提供的函数,这里是questionSubmit -> getQuestionSubmitVO(questionSubmit, loginUser)。这种写法被称为Lambda表达式,它允许你以一种更简洁的方式传递函数作为参数。在这里,questionSubmit -> getQuestionSubmitVO(questionSubmit, loginUser) 就是一个函数,它接受一个QuestionSubmit对象作为参数,并返回一个对应的QuestionSubmitVO对象。因此,.map(questionSubmit -> getQuestionSubmitVO(questionSubmit, loginUser)) 的作用就是将questionSubmitList中的每个QuestionSubmit对象映射为相应的QuestionSubmitVO对象。
在这段代码中,new Page<>(questionSubmitPage.getCurrent(), questionSubmitPage.getSize(), questionSubmitPage.getTotal()) 返回的是一个Page<QuestionSubmitVO>对象,而不是Page<QuestionSubmit>对象,这可能是因为在这个场景中,希望返回的是一个包含QuestionSubmitVO对象的分页结果,而不是原始的QuestionSubmit对象。
这种情况下,可能是因为需要将questionSubmitList中的QuestionSubmit对象转换为QuestionSubmitVO对象,并将其放入一个新的Page对象中进行返回。因此,通过创建一个新的Page<QuestionSubmitVO>对象,可以确保返回的分页结果中包含的是经过特定处理后的QuestionSubmitVO对象,而不是原始的QuestionSubmit对象。
配置文件参数读取
@RestController
在Spring框架中,使用@RestController注解标记的Controller类会将返回值自动转换为JSON格式进行传输。
当返回值为int、Integer、Long等基本数据类型或其包装类时,Spring会自动将其转换为JSON格式进行传输。
例如,当Controller方法返回int类型的数据时,Spring会将其转换为JSON格式进行传输:
@RestController
public class MyController {
@GetMapping("/getNumber")
public int getNumber() {
return 123;
}
}
在这个例子中,当访问/getNumber接口时,返回的数据会被转换为JSON格式,例如{"value": 123}。
因此,使用@RestController注解标记的Controller类会自动处理基本数据类型和包装类的返回值,将其转换为JSON格式进行传输。
分页查询
queryWrapper.ne 是 MyBatis-Plus 中的一个方法,用于生成 SQL 查询条件中的不等于(not equal)条件。它的作用是生成类似于 column_name <> value 的 SQL 查询条件。
数据库操作
更新数据库字段
方法中为什么每次更新数据库中questionSubmit的status字段时都要新new一个questionSubmit对象
在这个方法中,每次更新数据库中questionSubmit的status字段时都要新new一个QuestionSubmit对象的原因是为了确保每次更新的对象是独立的,避免可能出现的对象引用问题或者状态混乱的情况。如果重复使用第一次更新时的对象并重新设置不同的值,可能会导致对象状态的混乱或者不可预测的行为。
通过创建新的QuestionSubmit对象,可以确保每次更新操作都是基于一个新的干净对象进行的,从而避免潜在的错误或逻辑混乱。这种做法可以提高代码的可读性、可维护性和可靠性。
因此,虽然在理论上可以重复使用第一次更新时的对象并重新设置不同的值,但为了确保代码的健壮性和可靠性,建议每次更新数据库中的questionSubmit的status字段时都新new一个新的QuestionSubmit对象。
在MyBatis Plus中,是两种不同的操作:
save和update
- save操作:save操作用于向数据库中插入一条新的记录。如果插入的记录在数据库中已存在,则会抛出异常。在实际应用中,save方法通常用于插入新数据。
在MyBatis Plus中,插入数据并返回主键值的方法是save方法。当使用save方法成功插入数据后,会将生成的主键值设置到实体对象中,并可以通过实体对象获取到该主键值。
示例代码:
User user = new User();
user.setName("Alice");
user.setAge(25);
user.setEmail("alice@example.com");
userMapper.save(user);
Long primaryKey = user.getId(); // 获取插入数据的主键值
在上面的示例中,使用save方法成功插入数据后,可以通过实体对象的getId()
示例代码:
User user = new User();
user.setName("Alice");
user.setAge(25);
user.setEmail("alice@example.com");
userMapper.save(user);
- update操作:update操作用于更新数据库中已存在的记录。在MyBatis Plus中,update方法通常需要指定更新的条件,可以是根据主键更新,也可以是根据其他条件更新。在实际应用中,update方法通常用于更新已有数据。
示例代码:
User user = userMapper.selectById(1L);
user.setName("Bob");
user.setAge(30);
userMapper.updateById(user);
总结:
- save方法用于插入新数据,如果数据已存在会抛出异常;
- update方法用于更新已有数据,需要指定更新条件。
方法获取到插入数据的主键值。因此,save方法在插入数据后会返回主键值。
在实际开发中,根据具体业务需求选择使用save还是update方法。
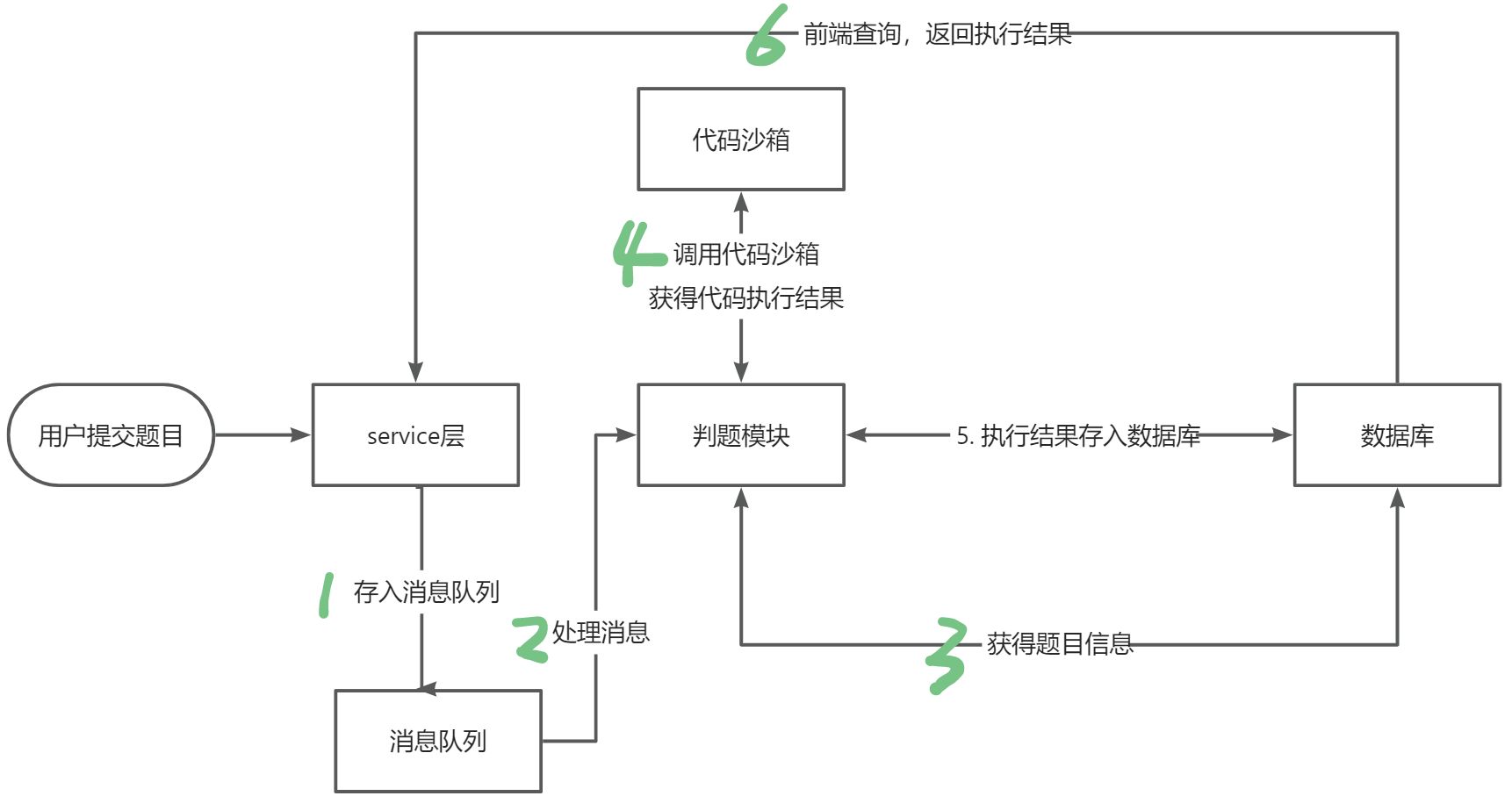
判题模块架构设计
逻辑关系:题目提交服务—>(调用了)判题服务模块—>(调用了)代码沙箱服务
判题模块需要调用调用代码沙箱运行代码,并进行题目运行结果正确与否的相关判断。
判题设计逻辑基础
不同的判题策略
根据不同的编程语言选择不同的判题策略(不同语言的不同特性决定了一道题正确与否不能依赖同一套判断逻辑,例如运行时间的限制,应根据不同的语言进行调整标准的判题时间)
工厂模式
代码沙箱调用策略
使用工厂模式选择 调用 哪种代码沙箱(远程/本地/第三方?)可根据yaml文件读取 type 的值从而创建不同的代码沙箱示例
代理模式
由于原本的沙箱只有执行代码的功能,如果我们调用沙箱服务时想在沙箱执行代码(调用executeCode方法)时增加其他功能,例如在方法执行前后打日志或记录其他信息,可以使用使用沙箱代理类来增强原本的沙箱的方法。
调用关系(实现方式)
- 在questionSubmitService的方法里调用JudgeService的doJudge方法
- 在JudgeService中调用JudgeManager的判题逻辑服务(包装了选择好判题策略的doJudge方法)
- 在JudgeManager(注册为service服务)中实现根据读取编程语言的类型进行创建不同的判题策略并进行dojudge方法的调用
- 编写不同的判题策略:每套执行语言实现一个判题策略方法,均实现JudgeStrategy接口的doJudge方法



JudgeServiceImpl

判题模块设计






判题参数设计
JudgeContext用于传递上下文参数


JudgeContext参数设计
service判题流程
- 从数据查询提交记录,判断判题状态
- 参数校验
- 更改判题状态为判题中
- 调用代码沙箱服务,运行代码
- 获取输出值
- 根据语言选择判题策略
- 校验输出值
- 判题状态更改, 判题结果存入数据库中
代码沙箱接口设计
- sandbox 接口 定义了代码沙箱调用执行代码的相关方法
- executeCodeResponse: 代码沙箱执行返回结果
- executeCodeRequest: 调用代码沙箱需要传入的dto类
- 传入的输入用例每组都有间隔 保存形式为list
- 传入的输入用例每组都有间隔 保存形式为list

架构设计逻辑图
JAVA原生代码沙箱实现
实用工具类
- 查看JVM运行情况小工具Jcon,可视化查看jvm运行情况,包括jvm回收,内存占用等
- hutool中自带的 wordTree 字典树,可以构建一个传入列表的字典树,可方便快速查找是否存在某个词
执行代码思路
执行代码程序思路
- 把用户传来的代码保存到特定的路径,作为java文件
- 使用Process类(java原生的命令行执行类),编译代码,得到class文件
- 执行代码,等待程序执行结束
- 根据Process的 Process.waitFor()方法获得程序执行结果的退出码
- 从Process对象获得InputStream对象获得控制台获取输出结果
- 保存正常结束程序或异常结束程序的控制台信息
Process类
Starts a new process using the attributes of this process builder.
The new process will invoke the command and arguments given by command(), in a working directory as given by directory(), with a process environment as given by environment().获取输出
在执行编译程序时指定编码参数,防止输出乱码
for循环执行命令
循环输入输入实例
收集输出结果 以及输出信息
使用spring提供的stopwatch计时 获取执行时间,使用最大时间来统计判题时间(or平均值)
运行内存信息难以获取,因为无法从Process类中获取到进程号,无法获知运行过程中子程序(用户代码)占用的内存空间运行计时
runStopWatch.start(); Process runProcess = Runtime.getRuntime().exec(runCmd); runStopWatch.stop();这行代码的执行时间会包括里面新进程执行指令的时间。当调用
Runtime.getRuntime().exec(runCmd)时,会启动一个新的进程来执行runCmd中指定的命令,整个过程会耗费一定的时间。因此,如果runCmd中的指令是一个耗时操作,那么整行代码的执行时间将会包括这部分耗时操作的时间。int exitValue = runProcess.waitFor();是的,
waitFor方法会导致当前线程等待,直到通过该Process对象执行的命令完成为止。一旦命令执行完成,waitFor方法会返回执行结果,然后你可以通过exitValue来获取命令的退出值。在等待的过程中,Process对象内部会记录命令的执行信息,包括执行结果、输出信息等。因此,你可以通过waitFor方法来等待命令执行完成,并获取相应的执行信息。
计时错误思路
在守护线程中实时监控cmd进程是否存活,并开启stopWatch计时
防止服务器内存空间不足,删除代码目录(或者存储数据库中)
FileUtil判断目录是否存在后删除
代码沙箱内部错误处理
封装一个错误处理方法,处理系统异常,当用户代码执行异常时也可以直接返回
安全设置
恶意操作
- 执行超时
- 占用内存
- 越权操作。。等操作
- 读取操作系统文件
- 写文件
- 删除文件
- 更改文件
- 执行文件
- 执行高危操作
java程序安全控制
- 超时控制
- 开启一个守护线程,计时,超过一定时间就杀死用户代码线程
- 限制资源分配
实际在执行程序时,你存达到JVM分配的最大堆内存之后程序就会自动报错
可以使用JVisualVM 或 JConsole (jdk中自带的)工具,连接到JVM虚拟机上可视化查看运行状态
在启动java程序时指定JVM的参数,限制最大堆空间大小
java -Xmx256m
但是-Xmx参数、JVM堆内存的限制,不等同于系统实际占用的最大资源(主线程占用内存)
更严格的内存限制,需要在系统层面限制,JVM层面的限制有限
Linux系统,可以使用cgroup来实现对某个进程的CPU,Memory等资源的分配
JVM常用启动参数
权限控制-黑白名单
定义黑名单,禁止敏感操作(例如调用File操作相关的函数)
结合wordTree字典树存储黑名单中单词,使用更少的空间存储更多的敏感词汇,并且实现更高效的词汇查找
字典树实现
使用hutool的字典树工具类,不需要自己构建字典树
使用静态代码块初始化一个全局字典树
将代码放到字典树里去匹配(WORD_TREE.matchWord(code)方法)
优点:
简单,易实现
缺点:
误判可能性高:关键词与自定义变量名冲突
对不同的编程语言、对应不同的领域,敏感词都不尽相同,建立完整全面的黑名单、维护黑名单成本高
Java安全管理器
java原生提供了安全管理器(Security Manager) 提供保护JVM,java程序的安全机制,可以实现比较全面的资源限制和权限限制操作
编写安全管理器
继承Sercurity Manager类
在禁止访问的方法处抛出异常
在程序中使用
我们需要在用户进程中限制权限而非在项目中限制权限操作(在外层调用会限制测试用例的读写和子进程的执行命令)
- 根据需要自定义自己的安全管理器
- 复制到 resource/security 目录下,移除类的包名
- 手动编译安全管理器类,得到class文件
- 在运行java程序时,指定安全管理器的class文件的路径、安全管理器的名称
java -Dfile.encoding=UTF-8 -cp %s;%s -Djava.security.manager=MySecurityManager Main这段命令是用来运行Java程序的。其中,-Dfile.encoding=UTF-8表示设置文件编码为UTF-8,-cp %s;%s表示设置classpath,-Djava.security.manager=MySecurityManager表示设置安全管理器为MySecurityManager,Main表示要运行的主类。
优点:
- 权限控制灵活
- 实现简单
缺点:
- 如果要做到更精细化的安全控制,需要较繁杂的逻辑设置,例如判断某些文件能读写,某些不可,麻烦
- 本质上还是java代码层面的安全限制,可能存在漏洞,层序层面的限制不如系统层面的限制深入
项目完成功能
- 系统架构:根据功能职责,将系统划分为负责核心业务的后端模块、负责校验结果的判题模块、负责编译执行代码的可复用代码沙箱。各模块相互独立,并通过 API 接口和分包的方式实现协作。
- 库表设计:根据业务流程自主设计用户表、题目表、题目提交表,并通过给题目表添加 userld 索2.引提升检索性能。(感兴趣的同学可以自己测试一下性能的提高比例)
- 自主设计判题机模块的架构,定义了代码沙箱的抽象调用接口和多种实现类(比如远程/第三方代3.码沙箱),并通过 静态工厂模式 + Spring 配置化 的方式实现了对多种代码沙箱的灵活调用。
- 使用 **代理模式 **对代码沙箱接口进行能力增强,统一实现了对代码沙箱调用前后的日志记录,减少重复代码
- 由于判题逻辑复杂、且不同题目的判题算法可能不同(比如 Java 题目额外增加空间限制),选用**策略模式 **代替 if else 独立封装了不同语言的判题算法,提高系统的可维护性。
- 使用 Java Runtime 对象的 exec 方法实现了对 Java 程序的编译和执行,并通过** Process 类 **的输入流获取执行结果,实现了Java 原生代码沙箱。
- 通过编写 Java 脚本自测代码沙箱,模拟了多种程序异常情况并针对性解决,如使用守护线程 +Thread.sleep 等待机制实现了对进程的超时中断、使用 JM -Xmx 参数限制用户程序占用的最大堆内存、使用 黑白名单 + 字典树 的方式实现了对敏感操作的限制。(选1-2 种即可)
- 使用 Java 安全管理器和自定义的 Security Manager 对用户提交的代码进行权限控制,比如关闭写文件、执行文件权限,进一步提升了代码沙箱的安全性。
- 为保证沙箱宿主机的稳定性,选用 Docker 隔离用户代码,使用 Docker Java 库创建容器隔离执9 .行代码,并通过 tty 和 Docker 进行传参交互,从而实现了更安全的代码沙箱。
- 使用 VMware Workstation 虛拟机软件搭建 Ubuntu Linux + Docker 环境,并通过 JetBrainsClient 连接虚拟机进行实时 远程开发,提高了开发效率。
- 为提高 Docker 代码沙箱的安全性,通过 HostConfig 限制了容器的内存限制和网络隔离,并通过设置容器执行超时时间解决资源未及时释放的问题。
- 由于 Java 原生和 Docker 代码沙箱的实现流程完全一致(编译、执行、获取输出、清理),选用12模板方法模式定义了一套标准的流程并允许子类自行扩展部分流程,提高代码一致性并大幅简化冗余代码。
- 为防止用户恶意请求代码沙箱服务,(采用 API签名认证的方式,)给调用方分配签名密钥,并通过校验请求头中的密钥保证了 API调用安全。
- 为保证项目各模块的稳定性,选用 Spring Cloud Alibaba 重构单体项目,(使用 Redis 分布式Session 存储登录用户信息,并将项目)划分为用户服务、题目服务、判题服务、公共模块。
- 使用阿里云原生脚手架初始化微服务项目,并结合 Maven 子父模块的配置,保证了微服务各模块依赖的版本一致性,避免依赖冲突。
- 通过工具(JetBrains 的 Find Usage 功能+表格整理)梳理微服务间的调用关系,并通过Nacos + OpenFeign 实现了各模块之间的相互调用,如判题服务调用题目服务来获取题目信息。
- 使用 Spring Cloud Gateway 对各服务接口进行聚合和路由,保护服务的同时简化了客户端的调用(前端不用根据业务请求不同端口的服务),并通过自定义 CorsWebFilter Bean 全局解决了跨域问题。
- 使用 Knife4j Gateway 在网关层实现了对各服务 Swagger 接口文档的统一聚合,无需通过切换地址查看各服务的文档。
- 为保护内部服务接口,给接口路径统一设置inner 前缀,并通过在网关自定义 GlobalFilter(全局请求拦截器)实现对内部请求的检测和拦截,集中解决了权限校验问题。
- 为防止判题操作执行时间较长,系统选用异步的方式,在题目服务中将用户提交id 发送给RabbitMQ 消息队列,并通过 Direct 交换机转发给判题队列,由判题服务进行消费,异步更新提交状态。相比于同步,响应时长由 xx 秒减少至 xx 秒,且系统 qps 提升了 xx%(需要自己使用JMeter 等工具进行测试)。
- 基于自己二次开发的 Spring Boot 初始化模板 + MyBatis X插件,快速生成图表、用户数据的增删改查。
这段文字主要描述了使用代理模式对代码沙箱接口进行能力增强,选用模板方法模式定义标准流程,并允许子类自行扩展部分流程。同时采用策略模式替代if else,独立封装不同语言的判题算法,以提高系统可维护性。通过Java Runtime对象实现编译和执行,并使用Process类的输入流获取执行结果,实现了Java原生代码沙箱。同时还介绍了通过Docker隔离用户代码,使用Docker Java库创建容器隔离执行代码,并通过tty和Docker进行传参交互,提高了代码沙箱的安全性。最后还提到了使用Spring Cloud Alibaba重构单体项目,划分为用户服务、题目服务、判题服务、公共模块,并通过Nacos+OpenFeign实现了各模块之间的相互调用等内容。
经过压缩
- 熟悉系统架构设计,包括后端模块、判题模块和代码沙箱的独立设计与协作。
- 精通库表设计,独立设计用户表、题目表、题目提交表,并通过索引优化检索性能。
- 自主设计判题机模块,实现代码沙箱的抽象调用接口和多种实现类,并采用静态工厂模式和Spring配置化实现多种代码沙箱的灵活调用。
- 使用代理模式对代码沙箱接口进行能力增强,统一实现日志记录,减少重复代码。
- 熟练运用策略模式,独立封装不同语言的判题算法,提高系统可维护性。
- 实现Java程序的编译和执行,通过Java Runtime对象的exec方法和Process类获取执行结果,构建Java原生代码沙箱。
- 模拟多种程序异常情况并解决,包括超时中断和最大堆内存限制等,提升代码沙箱的稳定性。
- 使用Java安全管理器和自定义Security Manager对用户提交的代码进行权限控制,提升代码沙箱的安全性。
- 通过Docker隔离用户代码,使用Docker Java库创建容器隔离执行代码,提高代码沙箱的安全性。
- 搭建Ubuntu Linux + Docker环境,通过JetBrainsClient进行实时远程开发,提高开发效率。
- 使用HostConfig限制容器的资源和网络隔离,并设置容器执行超时时间,提高Docker代码沙箱的安全性。
- 使用模板方法模式定义标准流程,允许子类扩展部分流程,提高代码一致性并简化冗余代码。
- 实现API签名认证,通过分配签名密钥和校验请求头保证API调用安全。
- 使用Spring Cloud Alibaba重构单体项目,划分为用户服务、题目服务、判题服务和公共模块,提高项目稳定性。
- 使用阿里云原生脚手架初始化微服务项目,并结合Maven子父模块配置,保证各模块依赖版本一致性。
- 通过Nacos和OpenFeign实现微服务之间的相互调用,提高系统的可扩展性。
- 使用Spring Cloud Gateway对各服务接口进行聚合和路由,简化客户端调用并解决跨域问题。
- 使用Knife4j Gateway实现各服务Swagger接口文档的统一聚合,提高文档查看效率。
- 通过在网关设置接口路径前缀和自定义GlobalFilter实现对内部请求的检测和拦截,解决权限校验问题。
- 使用异步方式发送消息至RabbitMQ消息队列,实现判题操作的异步处理,提升系统响应速度和QPS。
- 基于二次开发的Spring Boot初始化模板和MyBatis X插件,快速生成图表和用户数据的增删改查功能。
项目优化点
- 把微服务项目部署上线,参考教程:(如何快速部署微服务项目?保姆级教程
- 增加题目的通过数、提交数统计,计算通过率限制代码沙箱中最多允许同时启动的 Docker 容器数,防止系统过载(甚至还可以用池化技术复用
-
Docker容器)更多类型的代码沙箱实现,比如使用 A 进行判题?使用第三方服务(judge0 api)进行判题?5.反向压力:https://zhuanlan.zhihu.com/p/404993753,通过调用的服务状态来选择当前系统的策略(比如根据当前提交任务队列数来控制当前允许用户的最大提交数),从而最大化利用系统资源。 - 限制单个用户的同时最大提交数,合理分配资源。6.
7.限制单个用户的提交频率,可以通过 Redisson 或者 Sentinel 网关层限流实现。8.实现 ACM 模式(通过代码进行输入输出)的代码沙箱
9.用同样的思路或者 Linux 的 cgroup 语法实现一种其他编程语言的代码沙箱
10.实现 Special Judge 特判程序的逻辑
11.给判题过程中的每个测试用例增加一个独立的内存、时间占用的统计
12.可以使用 JWT Token 实现用户登录,在网关层面通过 token 获取登录信息,实现鉴权13.处理消息队列的消息重试,避免消息积压(可以选用死信队列)
Docker代码沙箱
- ubuntu桌面版安装代码沙箱google参考文章:
https://juejin.cn/s/ubuntu%E6%A1%8C%E9%9D%A2%E7%89%88%E5%AE%89%E8%A3%85docker
在 Ubuntu 桌面版上安装 Docker,可以按照以下步骤进行:
- 首先,打开终端并更新包列表:
sql 复制代码sudo apt-get update - 安装 Docker 的依赖项:
arduino 复制代码sudo apt-get install apt-transport-https ca-certificates curl software-properties-common - 添加 Docker 的 GPG 密钥:
arduino 复制代码curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - - 添加 Docker 的软件源:
bash 复制代码sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" - 再次更新包列表:
sql 复制代码sudo apt-get update - 安装 Docker:
arduino 复制代码sudo apt-get install docker-ce - 启动 Docker 服务:
sql 复制代码sudo systemctl start docker - 验证 Docker 是否成功安装:
css 复制代码docker --versiondocker的使用练习
linux用户添加到docker组
sudo groupadd docker #添加docker用户组 sudo gpasswd -a $XXX docker #检测当前用户是否已经在docker用户组中 sudo gpasswd -a $USER docker #将当前用户添加至docker用户组 newgrp dockerIdea远程开发
ssh简介
SSH:是一种安全通道协议,主要用来实现字符界面的远程登录,远程复制等功能(使用TCP的22号端口)。SSH协议对通信双方的数据传输进行了加密处理,其中包括用户登录时输入的用户口令。
在RHEL 5系统中使用的是OpenSSH服务器由openssh,openssh-server等软件包提供的(默认已经安装),并以将sshd添加为标准的系统服务。
SSH提供一下两种方式的登录验证:
1、密码验证:以服务器中本地系统用户的登录名称,密码进行验证。
2、秘钥对验证:要求提供相匹配的秘钥信息才能通过验证。通常先在客户机中创建一对秘钥文件(公钥和私钥),然后将公钥文件放到服务器中的指定位置。
注意:当密码验证和私钥验证都启用时,服务器将优先使用秘钥验证。
SSH的配置文件:
sshd服务的配置文件默认在/etc/ssh/sshd_config,正确调整相关配置项,可以进一步提高sshd远程登录的安全性。配置文件的内容可以分为以下三个部分: 1、常见SSH服务器监听的选项如下: Port 22 //监听的端口为22 Protocol 2 //使用SSH V2协议 ListenAdderss 0.0.0.0 //监听的地址为所有地址 UseDNS no //禁止DNS反向解析 2、常见用户登录控制选项如下: PermitRootLogin no //禁止root用户登录 PermitEmptyPasswords no //禁止空密码用户登录 LoginGraceTime 2m //登录验证时间为2分钟 MaxAuthTries 6 //最大重试次数为6 AllowUsers user //只允许user用户登录,与DenyUsers选项相反 3、常见登录验证方式如下: PasswordAuthentication yes //启用密码验证 PubkeyAuthentication yes //启用秘钥验证 AuthorsizedKeysFile .ssh/authorized_keys //指定公钥数据库文件查看远程服务器时候安装ssh服务、客户端、以及是否启动
一、检查是否开启SSH服务
因为Ubuntu默认是不安装SSH服务的,所以在安装之前可以查看目前系统是否安装,通过以下命令:
ps -e|grep ssh
输出的结果ssh-agent表示ssh-client启动,sshd表示ssh-server启动。我们是需要安装服务端所以应该看是否有sshd,如果没有则说明没有安装。
二、安装SSH服务
sudo apt-get install openssh-client 客户端
sudo apt-get install openssh-server 服务器
或者
apt-get install ssh
三、启动SSH服务
sudo /etc/init.d/ssh start
四、修改SSH配置文件
可以通过SSH配置文件更改包括端口、是否允许root登录等设置,配置文件位置:
/etc/ssh/sshd_config
默认是不允许root远程登录的,可以再配置文件开启。
sudo vi /etc/ssh/sshd_config
找到PermitRootLogin without-password 修改为PermitRootLogin yes (本人遇到过)
五、重启SSH服务
service ssh restart
即可通过winscp 、putty使用ROOT权限远程登录。
启用root用户:sudo passwd root //修改密码后就启用了。
客户端如果是ubuntu的话,则已经安装好ssh client,可以用下面的命令连接远程服务器。
$ ssh xxx.xxx.xxx.xxx
TLS证书配置
openssl req -newkey rsa:2048 -nodes -keyout key.pem -x509 -days 365 -out cert.pem
使用java程序操作docker
参考文章: https://www.hangge.com/blog/cache/detail_2547.html
- 首先配置docker API监听端口
- 编写docker.service文件
在 **Execstart=/usr/bin/dockerd**之后添加内容** -H tcp://0.0.0.0:2375 -H unix://var/run/docker.sock**
这两个url允许外部程序访问docker的API
95 sudo vim /lib/systemd/system/docker.service
96 systemctl daemon-reload
97 service docker restart
98 systemctl status docker.service
99 firewall-cmd --permanent --add-port=2375/tcp
100 sudo apt install firewalld
101 firewall-cmd --permanent --add-port=2375/tcp
102 firewall-cmd --reload
maven 依赖
<!--docker client begin-->
<dependency>
<groupId>com.github.docker-java</groupId>
<artifactId>docker-java</artifactId>
<version>3.0.14</version>
</dependency>
<dependency>
<groupId>javax.ws.rs</groupId>
<artifactId>javax.ws.rs-api</artifactId>
<version>2.1</version>
</dependency>
<dependency>
<groupId>org.glassfish.jersey.inject</groupId>
<artifactId>jersey-hk2</artifactId>
<version>2.26</version>
</dependency>
<!--docker client end-->
编写java程序
public static void main(String[] args) {
// 连接docker服务器
DockerClient dockerClient = DockerClientBuilder
.getInstance("tcp://192.168.70.130:2375").build();
// 获取服务器信息
Info info = dockerClient.infoCmd().exec();
String infoStr = JSONUtil.toJsonStr(info);
System.out.println(infoStr);
}
2 < 200
2 < Api-Version: 1.45
2 < Content-Length: -1
2 < Content-Type: application/json
2 < Date: Tue, 16 Apr 2024 05:37:47 GMT
2 < Docker-Experimental: false
2 < Ostype: linux
2 < Server: Docker/26.0.1 (linux)
2 < Transfer-Encoding: chunked
{"ID":"e0b1a727-f5ec-4427-b328-435208433dfe","Containers":0,"ContainersRunning":0,"ContainersPaused":0,"ContainersStopped":0,"Images":0,"Driver":"overlay2","DriverStatus":[["Backing Filesystem","extfs"],["Supports d_type","true"],["Using metacopy","false"],["Native Overlay Diff","true"],["userxattr","false"]],"Plugins":{"Volume":["local"],"Network":["bridge","host","ipvlan","macvlan","null","overlay"],"Authorization":null,"Log":["awslogs","fluentd","gcplogs","gelf","journald","json-file","local","splunk","syslog"]},"MemoryLimit":true,"SwapLimit":true,"CpuCfsPeriod":true,"CpuCfsQuota":true,"CPUShares":true,"CPUSet":true,"PidsLimit":true,"IPv4Forwarding":true,"BridgeNfIptables":true,"BridgeNfIp6tables":true,"Debug":false,"NFd":25,"OomKillDisable":false,"NGoroutines":42,"SystemTime":"2024-04-16T13:37:40.965237557+08:00","LoggingDriver":"json-file","CgroupDriver":"systemd","CgroupVersion":"2","NEventsListener":0,"KernelVersion":"6.5.0-27-generic","OperatingSystem":"Ubuntu 22.04.4 LTS","OSVersion":"22.04","OSType":"linux","Architecture":"x86_64","IndexServerAddress":"https://index.docker.io/v1/","RegistryConfig":{"AllowNondistributableArtifactsCIDRs":null,"AllowNondistributableArtifactsHostnames":null,"InsecureRegistryCIDRs":["127.0.0.0/8"],"IndexConfigs":{"docker.io":{"Name":"docker.io","Mirrors":[],"Secure":true,"Official":true}},"Mirrors":null},"NCPU":2,"MemTotal":2015797248,"GenericResources":null,"DockerRootDir":"/var/lib/docker","HttpProxy":"","HttpsProxy":"","NoProxy":"","Name":"lily-virtual-machine","Labels":[],"ExperimentalBuild":false,"ServerVersion":"26.0.1","Runtimes":{"io.containerd.runc.v2":{"path":"runc","status":{"org.opencontainers.runtime-spec.features":"{\"ociVersionMin\":\"1.0.0\",\"ociVersionMax\":\"1.0.2-dev\",\"hooks\":[\"prestart\",\"createRuntime\",\"createContainer\",\"startContainer\",\"poststart\",\"poststop\"],\"mountOptions\":[\"acl\",\"async\",\"atime\",\"bind\",\"defaults\",\"dev\",\"diratime\",\"dirsync\",\"exec\",\"iversion\",\"lazytime\",\"loud\",\"mand\",\"noacl\",\"noatime\",\"nodev\",\"nodiratime\",\"noexec\",\"noiversion\",\"nolazytime\",\"nomand\",\"norelatime\",\"nostrictatime\",\"nosuid\",\"nosymfollow\",\"private\",\"ratime\",\"rbind\",\"rdev\",\"rdiratime\",\"relatime\",\"remount\",\"rexec\",\"rnoatime\",\"rnodev\",\"rnodiratime\",\"rnoexec\",\"rnorelatime\",\"rnostrictatime\",\"rnosuid\",\"rnosymfollow\",\"ro\",\"rprivate\",\"rrelatime\",\"rro\",\"rrw\",\"rshared\",\"rslave\",\"rstrictatime\",\"rsuid\",\"rsymfollow\",\"runbindable\",\"rw\",\"shared\",\"silent\",\"slave\",\"strictatime\",\"suid\",\"symfollow\",\"sync\",\"tmpcopyup\",\"unbindable\"],\"linux\":{\"namespaces\":[\"cgroup\",\"ipc\",\"mount\",\"network\",\"p


直接使用docker编译执行
lily@lily-virtual-machine:~/oj-codeSandbox/execCode$ docker exec 5af9c3b31b87 javac /app/execCode/Main.java
lily@lily-virtual-machine:~/oj-codeSandbox/execCode$ docker exec 5af9c3b31b87 ls /app/execCode
Main.class
Main.java
c916edc6-70fd-490f-91f4-ca0b73633644
dfdb2e65-fab9-45df-a19b-d131473c4832
e352a4db-3046-4a9e-a576-b4ea414cc935
lily@lily-virtual-machine:~/oj-codeSandbox/execCode$ docker exec 5af9c3b31b87 java -cp /app/execCode Main 2 3
5
Hello World!
你好世界这是执行代码的输出结果
挂载对应目录
服务器: home/lily/oj-codeSandbox
docker: /app
编译命令:
改造微服务项目
微服务划分
业务模块
- 用户服务(lilyOj-user-service):
- 端口: 8102
- 注册
- 登录
- 用户管理增删改查相关
- 题目服务(lilyOj-question-service)
- port:8103
- 题目相关增删改查
- 在线做题
- 题目提交
- 判题服务(lilyOj-judge-service)
- prot:8104
- 判题模块执行较重的操作
- 执行判题逻辑
- 错误处理
- 开放接口(提供一个独立的新服务)
公共模块
common 模块(lilyOj-common):全局异常处理、请求响应封装类、公用工具类
model 模型模块(lilyOj-model): 公用实体类
服务公共接口模块(lilyOj-service-client):每个服务之间需要互相调用的接口依赖服务
服务注册中心:nacos
微服务网关(lilyOj-gateway):聚合所有的接口,统一接受处理前端的请求路由划分
使用springboot的context-path统一修改各接口的前缀
inner : 服务内部之间互相调用,网关层面限制外部调用
用户服务:
- /api/user
- /api/user/inner : 服务内部之间互相调用,网关层面限制外部调用
题目服务:
- /api/question
- /api/question/inner
判题服务:
- 业务类需要application.yml配置,主类复制启动注解
- 业务层需要controller service mapper代码
- 主类添加包扫描(compoentScan :把要使用的bean扫描注册到服务中,例如全局异常处理器,依赖于别的模块存在于com.lily包下)
- 保留service接口(对模块自身提供服务能力)
工具类模块
工具类模块是为业务模块提供实体类等服务的,工具类模块应该尽量不依赖于其他的工具类模块,避免造成第三方业务模块添加依赖时发生工具类模块循环依赖现象
mapper.xml时mybatis提供的用于定义数据库字段与实体类属性映射关系的文件,可以放置在model模块下,方便定义时进行映射父模块与子模块
- 父模块与子模块在pom.xml中应定义好子父依赖关系,在maven工具中可以查看子父模块是否成功绑定
- 父子模块使用的sdk应该是同一个版本甚至是同一个(进行编译运行操作),可以在project structure中对所有模块进行配置与修改
网关设计
Nacos
Nacos安装启动
安装
由于spring cloud版本为2021.0.5 查询对应的Nacos版本(服务注册发现中,便于管理已注册的服务的)
Nacos版本选择2.2.0版本
Nacos github下载地址:https://github.com/alibaba/nacos/releases/tag/2.2.0
nacos官网: https://nacos.io/en/docs/v2/what-is-nacos/
下载对应版本后解压即可启动
Nacos启动命令:
进入Nacos的安装目录的bin文件下
以standalone的形式启动Nacos,否则启动成功后会自行退出E:\nacos-server-2.2.0\nacos\bin> startup.cmd -m standaloneNacos程序启动后输入网址进入管理页面,默认账号密码均为 nacos
localhost:8848/nacos项目配置发现中心
每个需要对外提供服务的业务模块在application.yml中添加配置
# 发现中心配置 spring: cloud: nacos: discovery: server-addr: 127.0.0.1:8848 # 路由的划分 server: address: 0.0.0.0 port: 8103 servlet: context-path: /api/question给业务服务项目启动类增加注解,开启服务发现、找到对应的客户端的Bean的位置
springboot开启支持OpenFeign调用
添加OpenFeign配置